Big Data Web Console to build, manage and operate Big Data 2.0 clusters using Kubernetes.
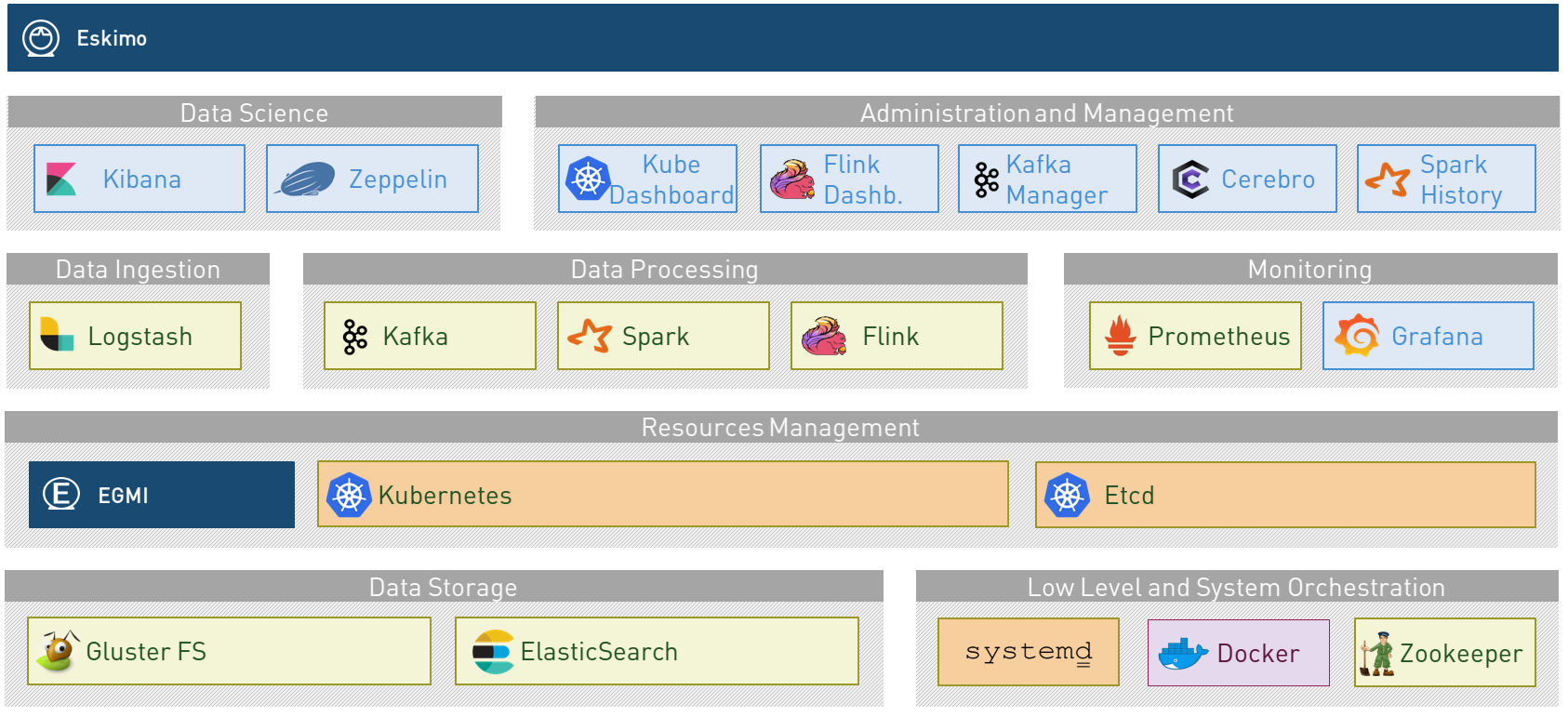
Eskimo Community Edition is 100% open source platform distribution, including
Apache Spark, Apache Flink and ElasticSearch and built specifically to meet Data
Science demands on Big Data.
Eskimo delivers everything you need for enterprise data science use right out of the box.
By integrating more than twenty critical open source projects in kubernetes and systemd,
Eskimo has created a functionally advanced system that helps you perform end-to-end Big
Data workflows without the hassle of maintaining and operating the Big Data cluster.
Kubernetes, also known as K8s, is an open-source system for automating deployment,
scaling, and management of containerized applications.
Designed on the same principles that allows Google to run billions of containers
a week, Kubernetes can scale without increasing your ops team.
Eskimo leverages on Kubernetes to deploy and distribute services, consoles and Web Applications across Eskimo cluster nodes. Eskimo provides virtual routing to the runtime node running services and wraps the HTTP traffic through SSH tunnels.
Apache Flink is an open-source stream-processing framework
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Apache Flink's dataflow programming model provides event-at-a-time processing on both finite and infinite datasets. At a basic level, Flink programs consist of streams and transformations. Conceptually, a stream is a (potentially never-ending) flow of data records, and a transformation is an operation that takes one or more streams as input, and produces one or more output streams as a result.
Apache Spark is an open-source distributed general-purpose cluster-computing framework. Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance.
Spark provides high-level APIs and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Elasticsearch is a distributed, RESTful search and analytics engine capable of addressing a growing number of use cases. As the heart of the Elastic Stack, it centrally stores your data so you can discover the expected and uncover the unexpected.
Elasticsearch lets you perform and combine many types of searches — structured, unstructured, geo, metric — any way you want. Start simple with one question and see where it takes you.
Eskimo leverages on Kubernetes to scale the ElasticSearch cluser throughout the Eskimo cluster nodes.
Apache Kafka is a distributed Streaming platform.
Kafka is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
Eskimo leverages on Kubernetes to scale the Kafka cluser throughout the Eskimo cluster nodes.
Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to your favorite "stash."
Logstash dynamically ingests, transforms, and ships your data regardless of format or complexity. Derive structure from unstructured data with grok, decipher geo coordinates from IP addresses, anonymize or exclude sensitive fields, and ease overall processing.
Eskimo provides server and command line support for logstash on Kubernetes.
Apache Zeppelin is a web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more.
Zeppelin is a multiple purpose notebook, the place for all your needs, from Data Discovery to High-end Data Analytics supporting a Multiple Language Backend.
Within Eskimo, zeppelin can be used to run flink and spark jobs, discover data
in ElasticSearch, manipulate files in Gluster, run python, Java, scala or shell
scripts, etc.
Eskimo takes care of deploying and maintaining Zeppelin on Kubernetes.
Kibana lets you visualize your Elasticsearch data and navigate the Elastic Stack so you can do anything from tracking query load to understanding the way requests flow through your apps.
Kibana gives you the freedom to select the way you give shape to your data. And you don’t always have to know what you’re looking for. With its interactive visualizations, start with one question and see where it leads you
Eskimo takes care of deploying and maintaining Kibana on Kubernetes.
Cerebro is an open source elasticsearch web admin tool.
Monitoring the nodes here includes all indexes, all the data nodes, index size, total index size, etc
Eskimo takes care of deploying Cerebro on kubernetes and connecting it to the ElasticSearch cluster.
Gluster is a free and open source software scalable network filesystem.
GlusterFS is a scalable network filesystem suitable for data-intensive tasks such as cloud storage and media streaming. GlusterFS is free and open source software and can utilize common off-the-shelf hardware.
Eskimo fully manages the Gluster infrastutcture and leverages on EGMI - Eskimo Gluster Management Interface - https://github.com/eskimo-sh/egmi to entirely automated all tasks related to Gluster bricks maintenance and making them available to the kubernetes pods.
Kafka Manager is a tool for managing Apache Kafka.
KafkaManager enables to manage multiples clusters, nodes, create and delete topics, run preferred replica election, generate partition assignments, monitor statistics, etc.
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination.
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications.
Grafana is the open source analytics & monitoring solution for every database.
Within Eskimo, Grafana is meant as the data visualization tool for monitoring purposes on top of Prometheus.
One can use Grafana though for a whole range of other data visualization use cases including data discovery, data analysis, etc.
Prometheus is an open-source systems monitoring and alerting toolkit.
Prometheus's main features are: a multidimensional data model with time series data identified by metric name and key/value pairs, PromQL - a flexible query language to leverage this dimensionality, automatic discovery of nodes and targets, etc.
Prometheus is the technical monitoring tool used by Eskimo.