A state of the art Big Data Analytics Infrastructure and Management Web Console to build, manage and operate Big Data 2.0 Analytics clusters on Kubernetes.

Eskimo is available as an open-source Community Edition (or Eskimo CE) under the terms
of the Affero GPL license
or a commercial Enterprise Edition.
Eskimo Community Edition is free to use without any warranty under the terms of the Affero GPL license as long as
one develop activities involving Eskimo with full disclosure of the source code of one's own product,
software, platform, use cases or scripts and doesn't use it as part of a commercial product,
platform or software.
Please
for any additional information about commercial licenses.
Eskimo is first and foremost a unified, extensible and state of the Art Data Science Environment.
Data Scientists use Eskimo for all their Data Science Needs, from Data discovery to Analytics development and testing through Data Visualization, etc.
Analytics Applications are then promoted to production grade processes and operated on Eskimo in a unified way.


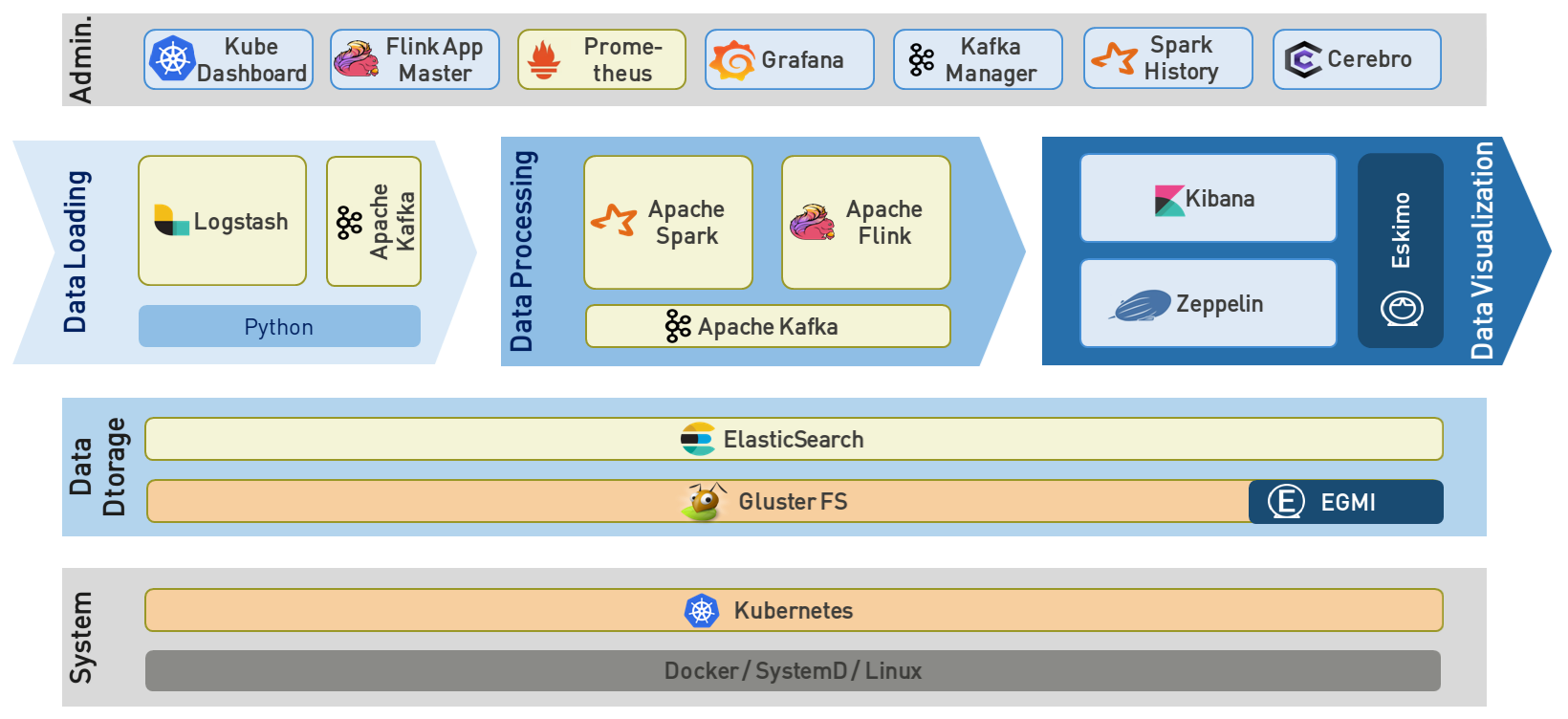
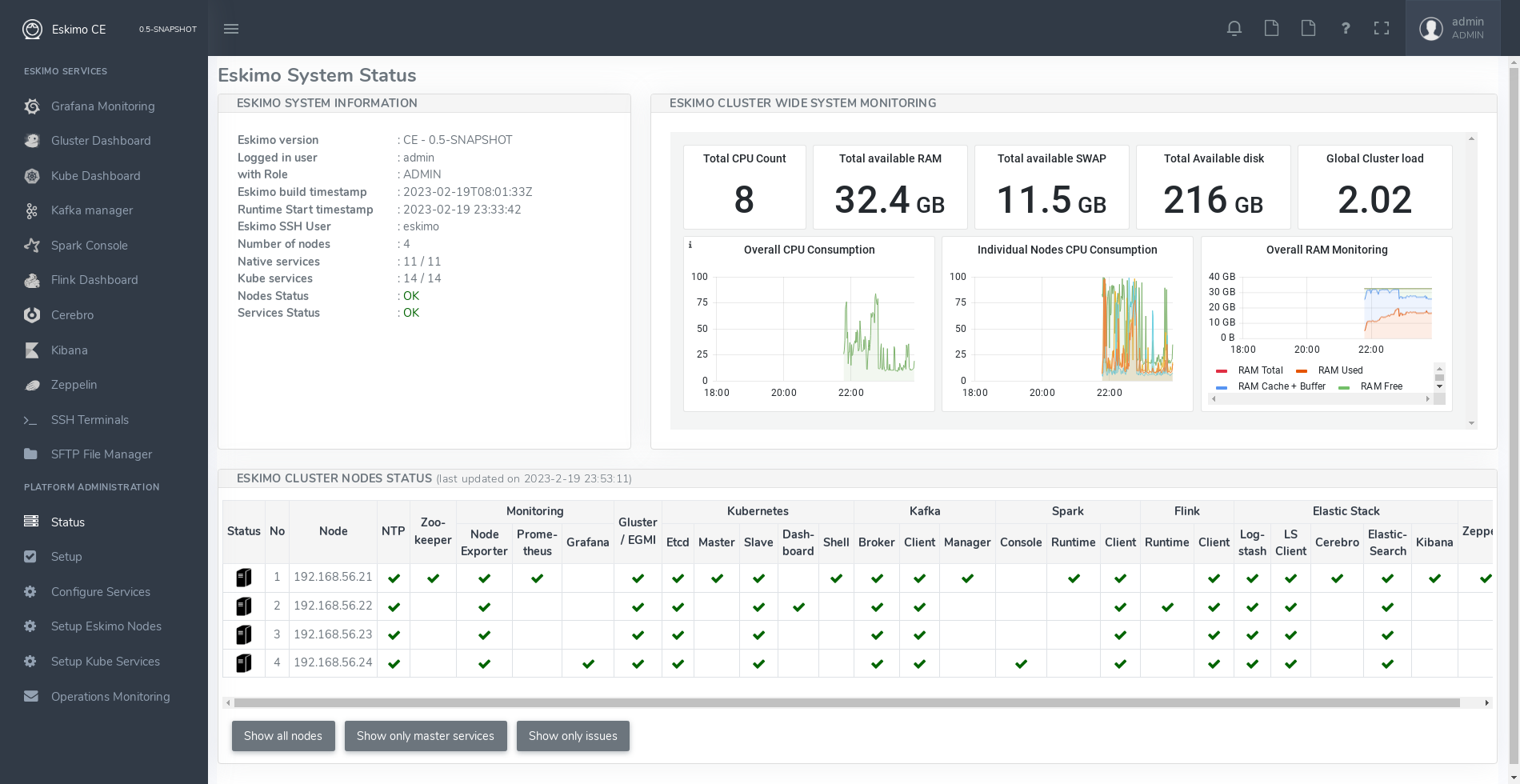
Eskimo's tip of the iceberg is its flagship web console.
The Eskimo Console is the single and only entry point to all your cluster operations, from services installation and maintenance to Data Analytics development, through Business dashboard creation, etc.
The Eskimo Console also provides SSH consoles, File browser, integrated File Edition, etc.
Just define which services you want to run and let eskimo take care of everything (installation, deployment, configuration, monitoring, etc.)
Don't bother where your services, consoles and UI applications run on the cluster, Eskimo wraps them all in a single UI.
High Availability comes out of the box. Limit your maintenance operations on the cluster to the strict minimum.

Eskimo packages the required monitoring, administration and notebook applications and consoles for you and makes them available in its own User Interface.
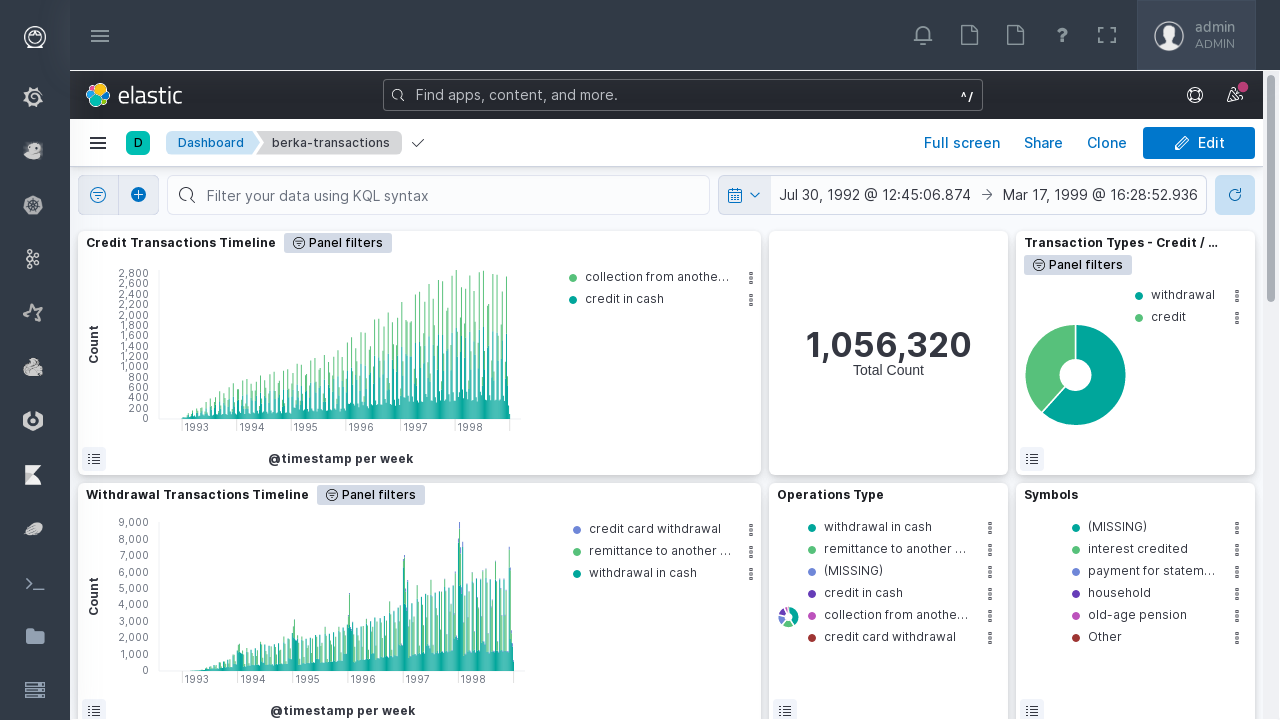
Elastic Kibana is the key visualization tool on the Eskimo Platform, and much more
Administration tool to deploy and manage your Big Data components on your cluster nodes.
Packaged services settings management.
Eskimo SFTP File Manager to administer your cluster nodes.
Fully functional Web-based SSH Console in Eskimo.
Kubernetes Dashboard in Eskimo to monitor your resources and PODs.
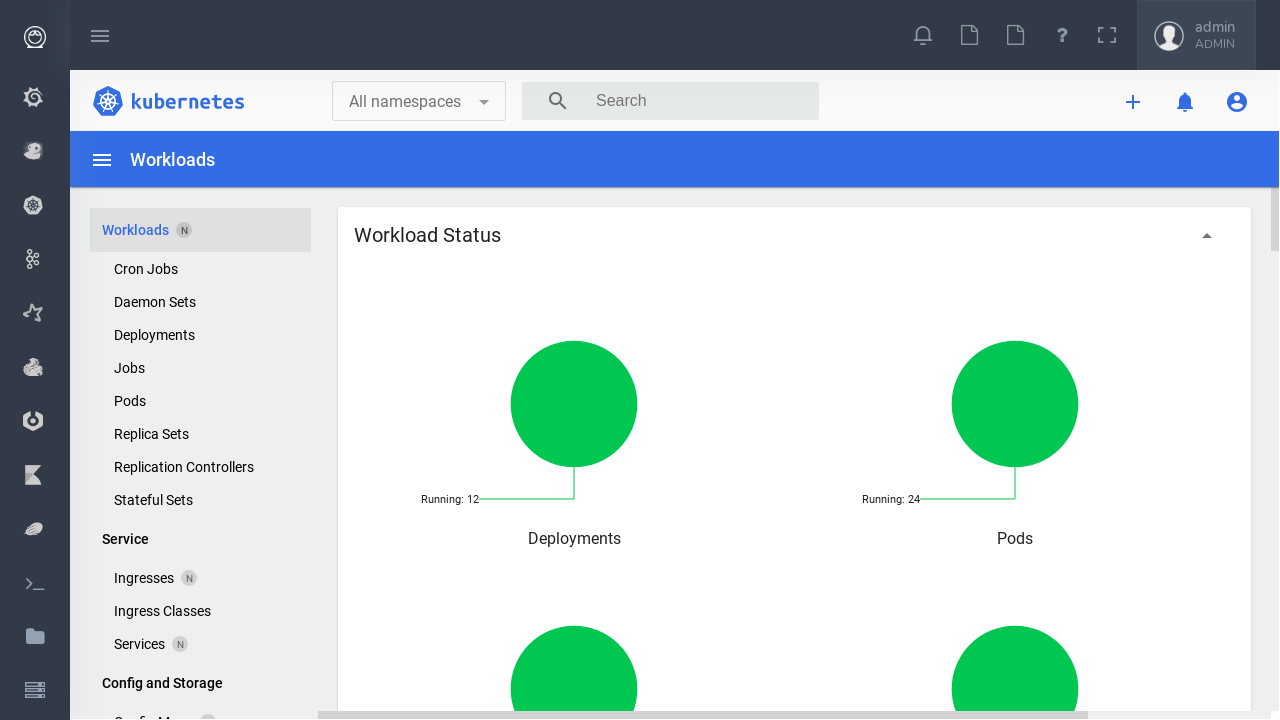
Kafka Manager in Eskimo to manage your kafka topics.
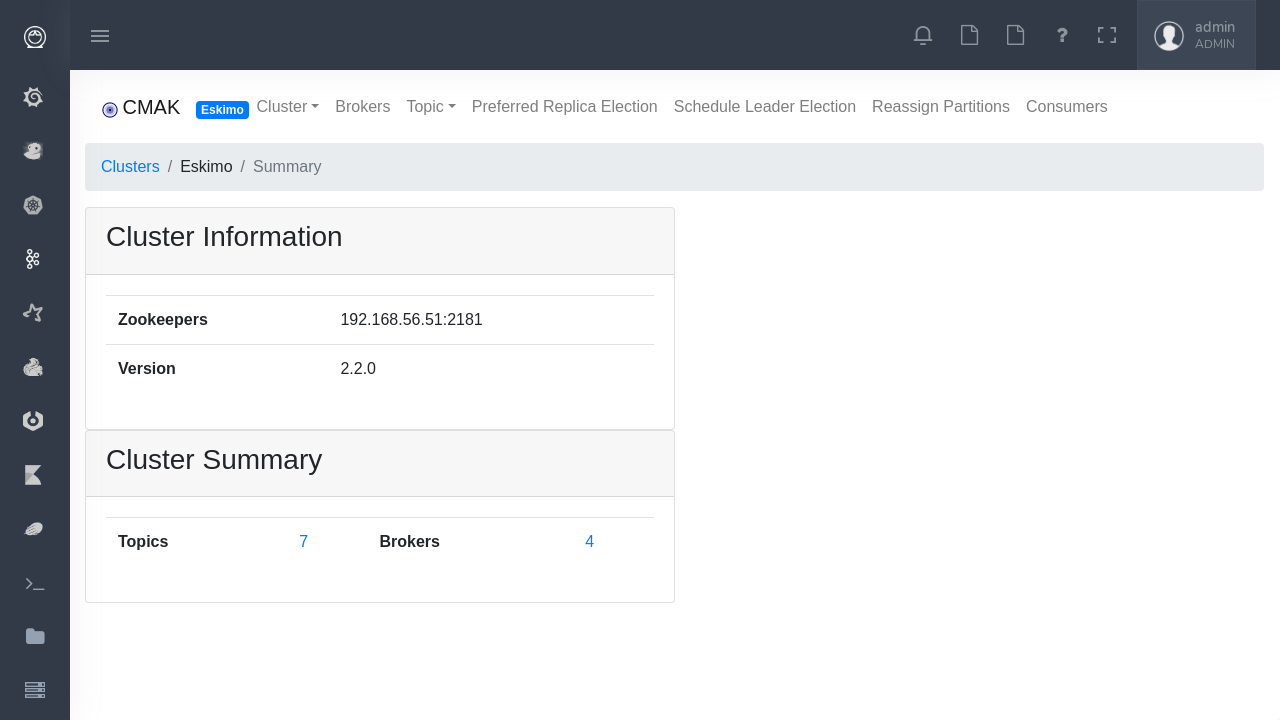
Spark UI in Eskimo to monitor your spark processes.
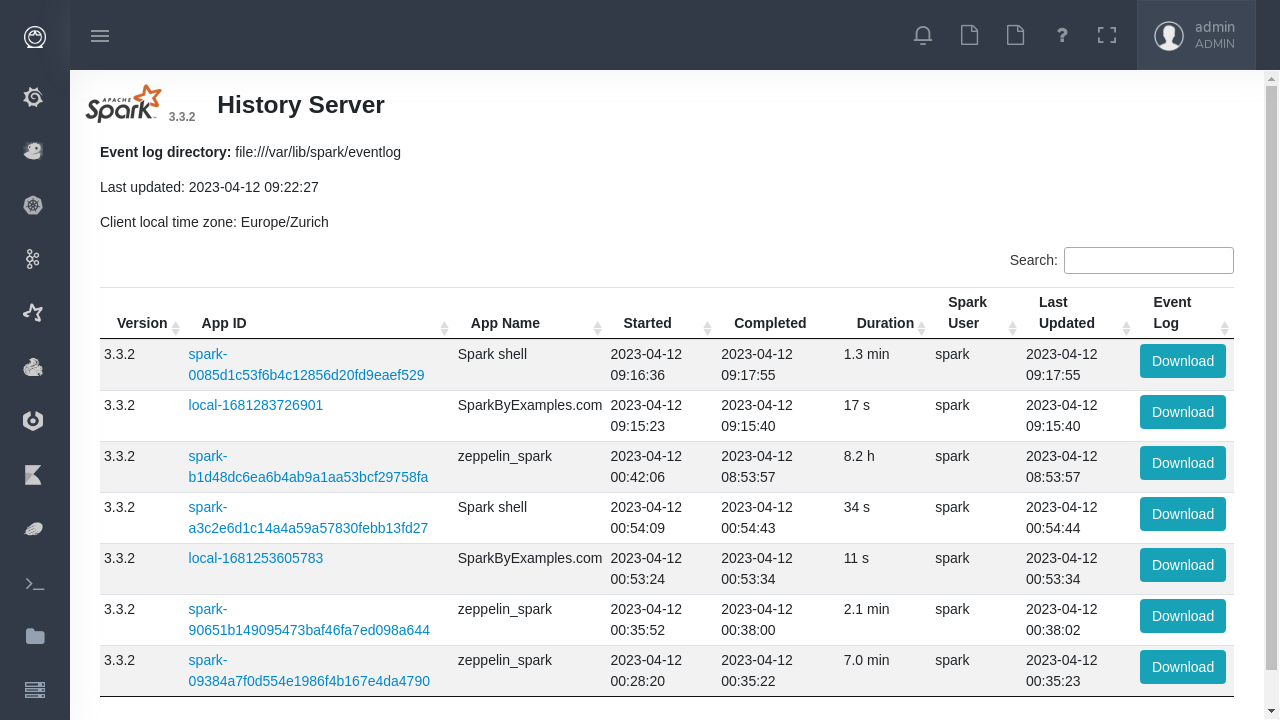
Flink App Master in Eskimo to managed and monitor your flink processes.
With eskimo, Big Data Scientists can prototype and run their analytics use cases on a thousand nodes cluster should they need it.
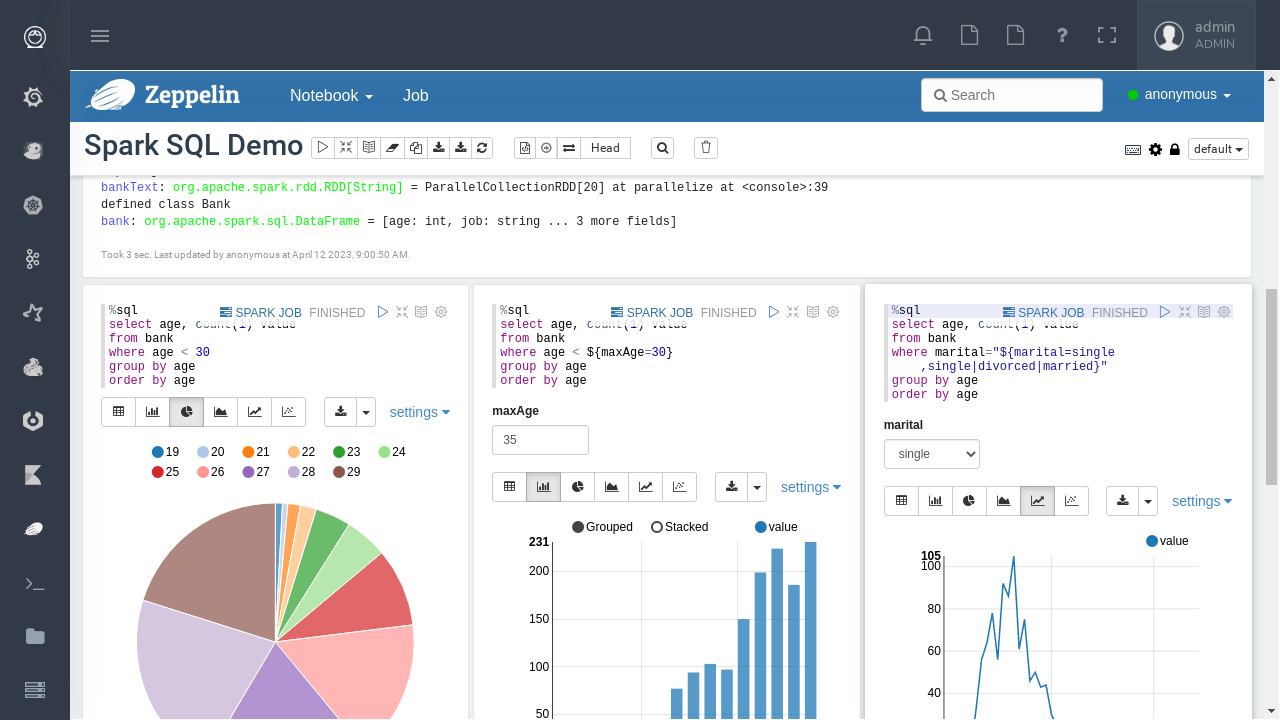
With Fink ML and Spark ML natively available on Flink and Spark and usable from within Zeppelin, Data Scientists can bring their mission to the next level: the big data way.
SciKit Learn and TensorFlow are also available from within Zeppelin of course.

In contrary to popular Hadoop-based and other Big Data Platforms, Eskimo is based on cutting-edge technologies:
- GlusterFS instead of HDFS
- Spark instead of Hive and Pig
- Kubernetes instead of Yarn
- Docker instead of native deployment
- ElasticSearch instead of HBase
- Flink instead of Storm
- Plus Zeppelin, Kibana, Logstash, etc.

Making gluster, elasticsearch, kafka, spark, zeppelin, etc. all work perfectly together is all but simple.
Eskimo takes care of everything and fine tunes all these services to make them understand each other and work together.
Eskimo enables you one-click administration of all of them, moving services, provisioning nodes, etc.
Yet it's open : open-source and built on standards

Do you want to build a production grade Big Data Processing cluster with thousands of nodes in the cloud and use it to analyze the internet ?
Or do you want to build a small AI laboratory on your own laptop to develop for your Data Science Research ?
Eskimo is made for you in these both cases, and many others.

Most Big Data Processing Platforms on the market today are Behemoths.
Eskimo leverages on Gluster, Kubernetes, Spark, Flink, Elasticsearch, Logstash, Kibana, Zeppelin, etc. - simple and extremely lightweight components that have a broad use cases coverage while simplifying administration, operation and usage compared to a full hadoop stack.

Eskimo works out of the box. Yet, Eskimo is not a black box, it's an open platform. One can fine tune and adapt everything exactly as desired: from the docker containers building to the services setup on the platform.
Want to leverage on eskimo to integrate other services such as Apache Storm or Cassandra? Declare your own services and import your own containers.

Eskimo is exhaustively built on top of Docker.
Only kubernetes need to be adapted and installed natively on the linux hosts running your
cluster
nodes.
All the other components - from kafka to zeppelin through spark - run on docker and mostly through Kubernetes.
Eskimo is successfully tested on Ubuntu, Debian, CentOS and Fedora nodes so far ... more are coming.
Eskimo is designed for Enterprise deployments, fulfilling enterprise-grade requirements:
- Security from the grounds-up: data and communication encryption, firewall,
authentication
and authorization on every action, etc.
- DRP compliance / Backup and restore tooling
- High-Availability out of the box
- State of the art Integration abilities
- Very broad range of use-cases and possibilities

Build your own Big Data Cloud
Eskimo is VM friendly.
You have a bunch of VMs somewhere on Amazon or google cloud ?
Deploy Eskimo and make it a state of the art big data 2.0 cluster, your way, not amazon
or
google's predefined, fixed and constraining way
Choose your services, define your cluster topology and let eskimo take care of everything
Apache Zeppelin is packaged with all required interpreters properly configured.